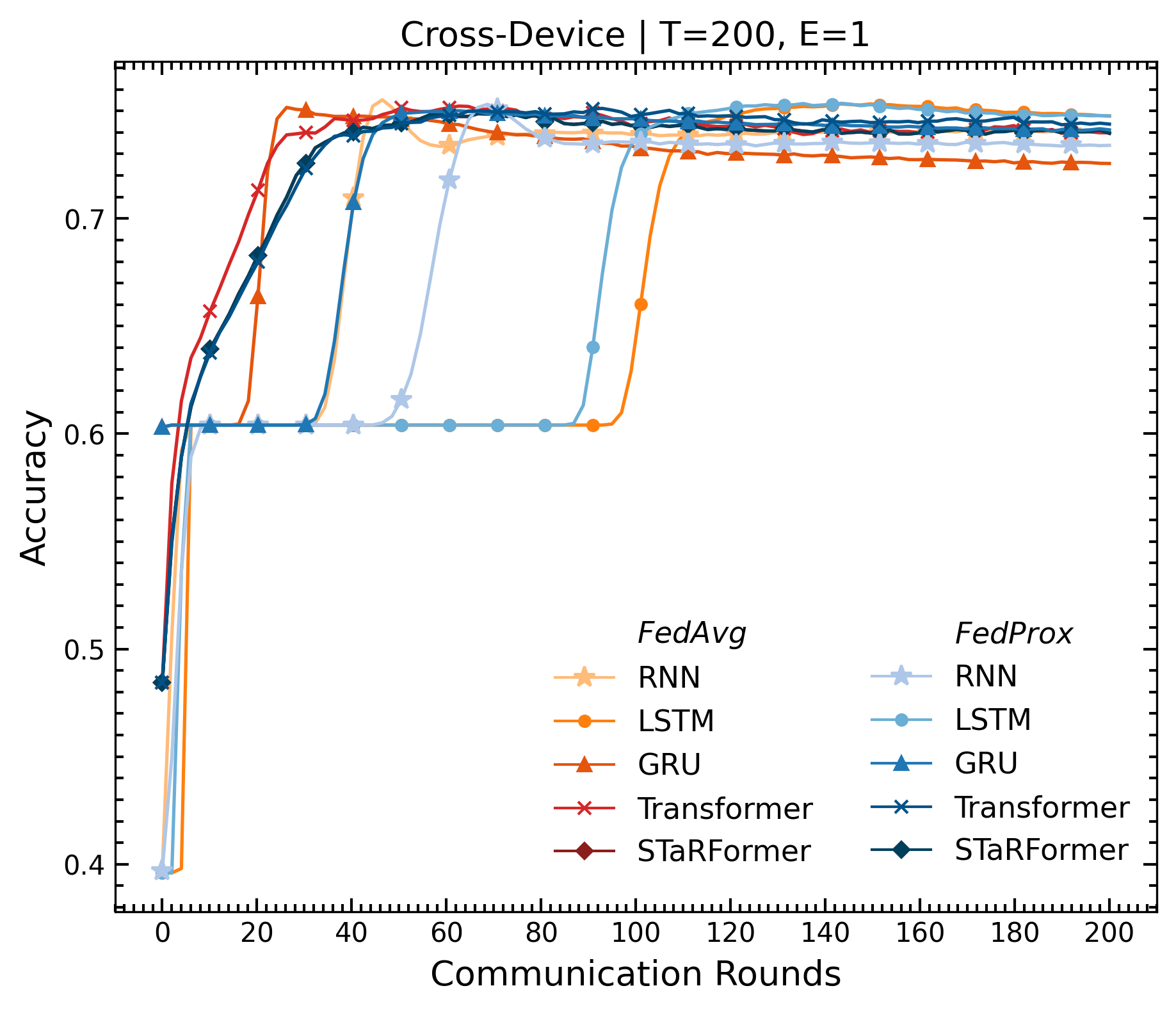
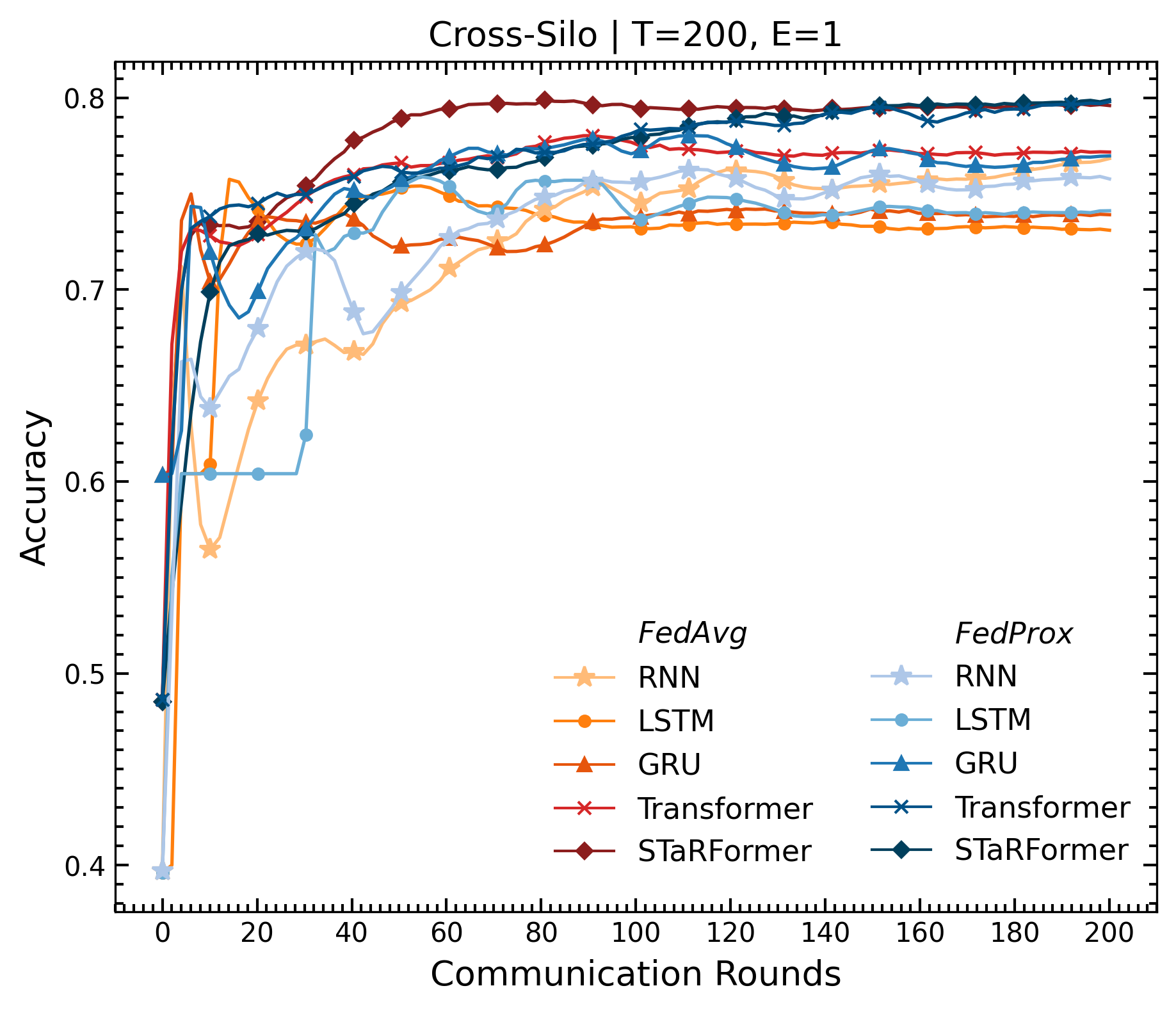
Over the past decade, advancements in machine learning, particularly large language models like OpenAI’s Chat- GPT, have heightened public awareness about artificial intelligence. The growing awareness has led to increased expectations for intelligent products that enhance user experience, often requiring the collection of substantial amounts of potentially sensitive data. However, data protection legislation such as the EU AI Act [1] or GDPR [2] restricts the collection and storage of sensitive user data in real-world applications, making it difficult for organizations to aggregate large datasets across users or institutions, in addition to substantial transmission costs associated with storing the data in the first place. Federated Learning offers a promising paradigm to address these issues by enabling decentralized learning via data minimization, thereby also re- ducing communication overhead. To evaluate its effectiveness, we explore a real-world sequential classification task to learn the intent of smart device users within confined areas of a vehicle. Utilizing an anonymized real-world dataset sourced from BMW’s car fleet and employing a novel sequential modeling approach, STaRFormer [3], we analyze two federated learning architectures, cross-device and cross-silo, and assess two federated aggregation algorithms for various baseline models. The results demonstrate that STaRFormer outperforms baseline models in the cross-silo case and delivers competitive results in the cross-device case, highlighting its efficacy in decentralized sequential data modeling.
The motivation for this project is rooted in the pursuit of data-driven solutions, necessitated by the abundant amounts of data generated by modern vehicles, which can reach gigabytes per hour. Mandated by General Data Protection Regulation (GDPR) [2], the European Union Artificial Intelligence Act [1] and other legistlation the data collection is often contingent upon obtaining customer consent. Moreover, the financial implications related to data storage and transmission are considerable, posing additional challenges. In the use-case presented, data availability further complicates the landscape, as merely around 30% of customers provide consent for the use of their data in developmental endeavors. This limitation prompts the need for strategies to effectively leverage potentially unavailable data. Additionally, the diversity in regulations across various countries adds layers of complexity to forming a cohesive data collection and storage strategy. These challenges collectively highlight the necessity for innovative approaches to enhance data utilization in vehicle technology development.
This project shows that local contrastive learning can improve Transformer model performance in federated learning for sequential tasks, but requires sufficient local data and careful tuning to avoid overfitting. Future work might explore methods to better balance global and local representation learning in distributed settings.
| Statistics | |||||||
|---|---|---|---|---|---|---|---|
| Setting | Evaluation Criterion | Accuracy | F0.5-Score | F1-Score | Precision | Recall | Avg. Rank (Accuracy) |
| Cross-Device | RNN | 0.720 | 0.706 | 0.695 | 0.726 | 0.702 | 4.375 |
| LSTM | 0.701 | 0.624 | 0.631 | 0.624 | 0.664 | 3.375 | |
| GRU | 0.736 | 0.724 | 0.719 | 0.647 | 0.720 | 2.375 | |
| Transformer | 0.743 | 0.729 | 0.717 | 0.743 | 0.718 | 2.500 | |
| STaRFormer | 0.740 | 0.726 | 0.714 | 0.741 | 0.711 | 2.375 | |
| FedAvg vs FedProx | 5 / 5 | 5 / 5 | 5 / 5 | 2 / 5 | 4 / 5 | - | |
| E=1 | 0.722 | 0.680 | 0.675 | 0.658 | 0.686 | - | |
| E=5 | 0.734 | 0.724 | 0.715 | 0.735 | 0.719 | - | |
| Cross-Silo | RNN | 0.746 | 0.737 | 0.736 | 0.741 | 0.740 | 4.250 |
| LSTM | 0.748 | 0.738 | 0.736 | 0.744 | 0.739 | 4.000 | |
| GRU | 0.743 | 0.732 | 0.730 | 0.734 | 0.732 | 3.250 | |
| Transformer | 0.758 | 0.746 | 0.741 | 0.751 | 0.743 | 3.250 | |
| STaRFormer | 0.770 | 0.758 | 0.754 | 0.762 | 0.752 | 1.250 | |
| FedAvg vs FedProx | 2 / 5 | 2 / 5 | 2 / 5 | 2 / 5 | 2 / 5 | - | |
| E=1 | 0.754 | 0.743 | 0.741 | 0.745 | 0.741 | - | |
| E=5 | 0.752 | 0.752 | 0.738 | 0.748 | 0.741 | - | |
| Settings | Aggregation | λCL | Accuracy | F0.5-Score | F1-Score | Precision | Recall |
|---|---|---|---|---|---|---|---|
| Cross-Device | FedAvg | 0.1 | 0.743 | 0.723 | 0.722 | 0.735 | 0.718 |
| 1.0 | 0.728 | 0.702 | 0.687 | 0.718 | 0.683 | ||
| FedProx | 0.1 | 0.743 | 0.729 | 0.722 | 0.735 | 0.718 | |
| 1.0 | 0.721 | 0.701 | 0.687 | 0.718 | 0.683 | ||
| Cross-Silo | FedAvg | 0.1 | 0.763 | 0.759 | 0.750 | 0.752 | 0.749 |
| 1.0 | 0.784 | 0.773 | 0.770 | 0.776 | 0.762 | ||
| FedProx | 0.1 | 0.744 | 0.722 | 0.729 | 0.735 | 0.719 | |
| 1.0 | 0.752 | 0.738 | 0.729 | 0.748 | 0.724 |
[1] C. of European Union, “Regulation (EU) 2024/1689 of the European Parliament and of the Council of 13 June 2024 laying down harmonised rules on artificial intelligence and amending Regulations (Artificial Intelligence Act),” Jun. 2024, legislative Body: CONSIL, EP.
[2] C. of European Union, “Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation),” 2016, doc ID: 32016R0679 Doc Sector: 3 Doc Type: R.
[3] M. Forstenhäusler, D. Külzer, C. Anagnostopoulos, S. P. Parambath, and N. Weber, “STaRFormer: Semi-Supervised Task-Informed Representation Learning via Dynamic Attention-Based Regional Masking for Sequential Data,” Apr. 2025, arXiv:2504.10097 [cs]. [Online]. Available: http://arxiv.org/abs/2504.10097